Upload date
All time
Last hour
Today
This week
This month
This year
Type
All
Video
Channel
Playlist
Movie
Duration
Short (< 4 minutes)
Medium (4-20 minutes)
Long (> 20 minutes)
Sort by
Relevance
Rating
View count
Features
HD
Subtitles/CC
Creative Commons
3D
Live
4K
360°
VR180
HDR
783 results
STSW02 | Prof. Johannes Schmidt-hieber | Statistical theory for deep neural networks with ReLU activation function Speaker: ...
7 views
3 weeks ago
If we stack thousands of layers of neurons without activation functions, what do we get? We get a single linear regression model.
1,138 views
In this video, we break down the AlexNet convolutional neural network architecture layer by layer. We cover convolutions, pooling, ...
276 views
11 days ago
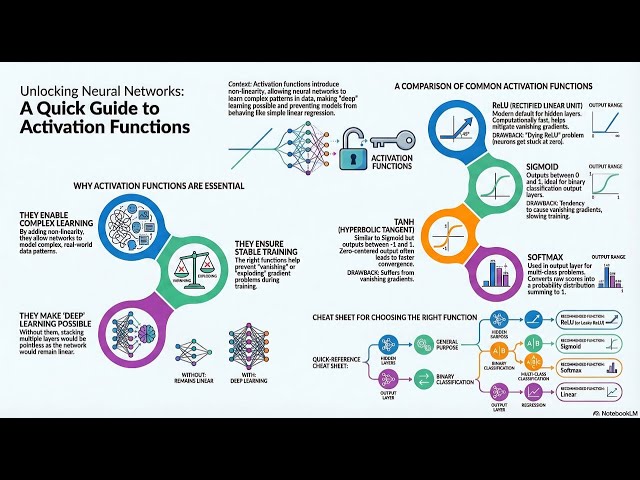
Activation Functions are the heart of Neural Networks. Without them, AI models would be dumb, linear, and unable to learn ...
1 month ago
ReLU looks simple, but it changes geometry. In this video, I show how a tiny 2D ReLU network turns a straight decision line into a ...
42 views
Hello everyone, this is my first video about artificial intelligence. I'm going to show you the biological support behind the ReLU ...
ReLU (Rectified Linear Unit) is fundamental in Convolutional Neural Networks (CNNs) because it introduces crucial non-linearity, ...
24 views
4 weeks ago
In this video, we showcase how bleaching trays can be designed using Relu's AI-powered dental design service Bleaching Trays.
Activation functions are what give neural networks the power to learn complex, real-world patterns. In this video, we break down ...
53 views
13 days ago
Unravel the critical function of ReLU (Rectified Linear Unit) in Convolutional Neural Networks. This video breaks down how this ...
0 views
Ever wondered about the secret sauce behind powerful neural networks? This video breaks down the crucial differences between ...
Original Video: https://www.youtube.com/watch?v=pzOEx4x1EYw&list=PL0Vz403YCedh7XaXqJSS90ezoHAtRe_HU&index=3.
Title: The Role of Linear Layers in Nonlinear Interpolating Networks Speaker: Professor Rebecca Willett (University of Chicago) ...
MDLW01 | Prof. Johannes Schmidt-hieber | Convergence rates of deep ReLU networks for multiclass classification Speaker: ...
8 views
Welcome to Phase 2: Neural Networks. In this video, we move from Standard Statistics to Deep Learning. I explain how a ...
7 days ago
Writing a CUDA kernel requires a shift in mental model. Instead of one fast processor, you manage thousands of tiny threads.
240 views
This lecture introduces the ReLU (Rectified Linear Unit) and Leaky ReLU activation functions, which are among the most widely ...
3 days ago
What is an activation function and why is it so important in neural networks? In this video, you'll understand the concept of ...
68 views
... might use a variant like leaky relu that preserves some negative values but standard relu is the workhorse The sigmoid function ...
27 views
This is a omprehensive overview of neural network history and modern implementation using the Keras library. One section traces ...
5 views